
Back in 2016, we highlighted a number of simple measures which you can carry out to improve the performance of a website. We hope part one was helpful – now here’s part two!
Unnecessary pages in the index
Do you want your data protection declaration or your About page to appear in Google? Fine, there’s no harm in that but it’s not really necessary either. And what’s more, it uses up the index budget. Google will find and crawl those pages but they don’t have to be indexed. This frees up place for more important URLs which really should be indexed but can’t because the budget has been used up. This is not to be confused with the crawl budget. Google assigns a crawl budget and an indexing budget to each site. The crawling budget tells the search engine how many pages can be crawled and is not specified by Google. The second budget determines how many pages can be indexed.
So what can you do? Pages which are irrelevant for SEO can be set to NOINDEX in the meta-robots details and excluded from the index. Such sites include log-in pages, terms and conditions, about us pages, data protection, shopping basket and checkout pages and pages with legitimate duplicate content – e.g., identical product descriptions for products in different colours or sizes.
Content blocked by robots.txt
The best way to convey instructions to bots is by using robots.txt, a simple text file uploaded to a website’s root directory. The file contains information on which files or folders should NOT be crawled, blocking out bots. Meta-robots commands such as NOINDEX will not even be read by crawlers. But remember: robots.txt commands are not binding, although search engines do tend to stick to the rules.
When creating your robots.txt, make sure that Google can read CSS and JavaScript files. The search console highlights any errors for you. Make sure to make this directory crawlable and test your most current file in the search console, as follows:
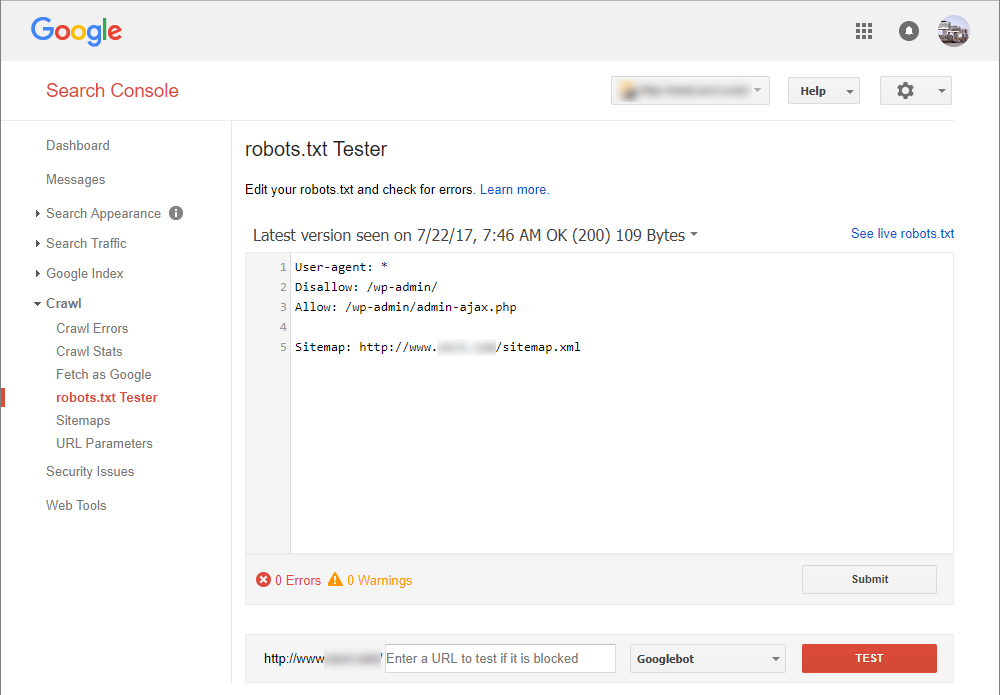
Should any errors remain, these will be shown in the tool for you to check again.
A few weeks ago, we went into more detail on robots.txt files on the XOVI Blog – so head over there and check it out for more information.
Internal links
Internal links are a great SEO tool. Since the integration of the Penguin algorithm into Google’s core algorithm, the issue of link building has been a subject of great conjecture. Put simply, building external links is recommended as long as they are genuinely valuable. However, webmasters and SEOs frequently underestimate the power of internal links, despite the fact that they are just as important for search engines as external links. The big advantage of internal links is that you don’t need to worry about the negative consequences of over-using big money-keywords. The search console also features a tool for the analysis of internal links:
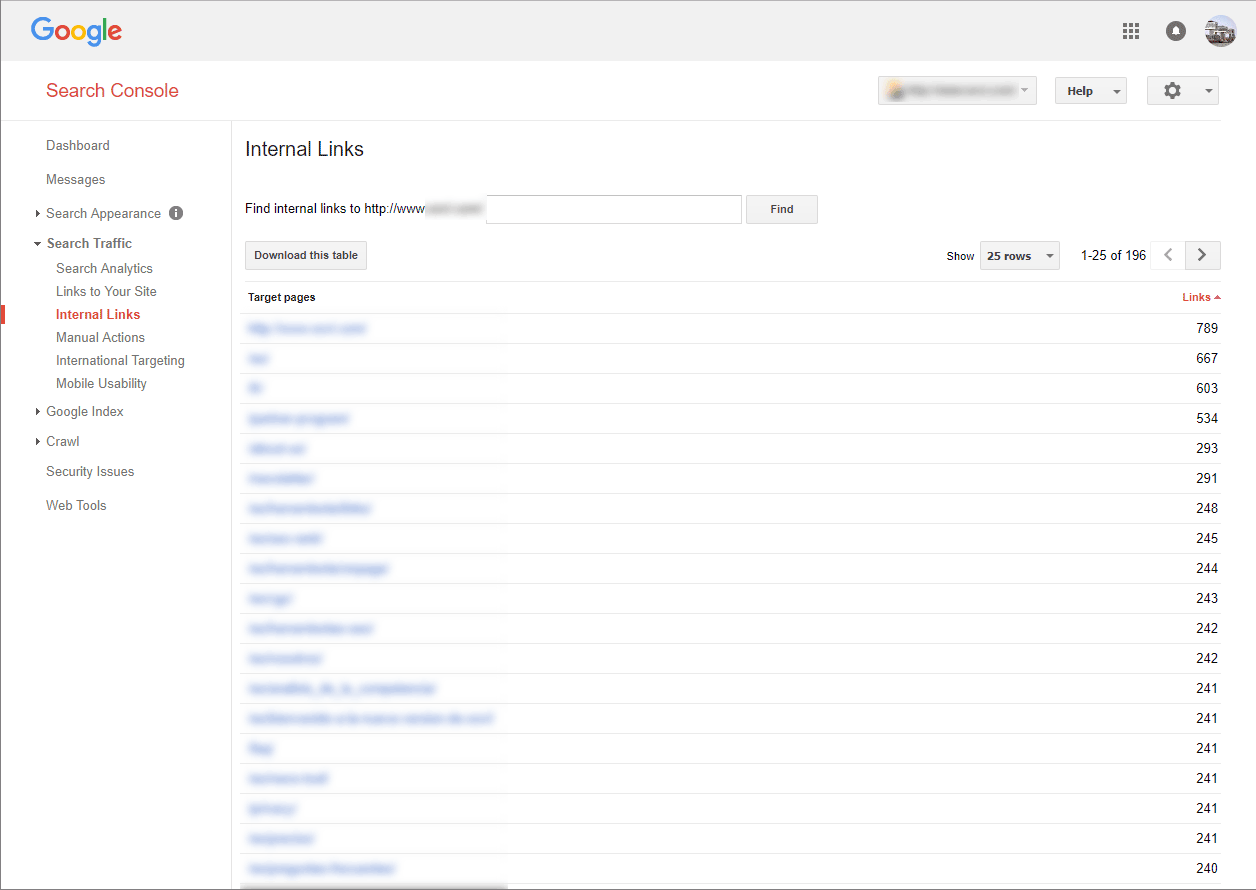
Here, you can see the pages which are most frequently linked. If you find your “About” page or a contact page listed here, then you need to act. Logic dictates that the most frequently linked sites are the most important so, with some intelligent link-building, you can make Google aware of your most important content and increase its relevance. .
URL structure (talking URLs)
Take a closer look at your URL structure. Admittedly, it’s not a ranking factor and the length of the URL itself is fundamentally irrelevant from a technical SEO point of view. After all, Google themselves say that any URL with up to 1,000 characters can be read easily – but we still tend to go for short, “talking” URLs. Why?
Put simply, talking URLs are web addresses which can be easily and normally read. They don’t include parameters and certainly shouldn’t feature special characters. Yet a URL can also be used to implant a keyword that you want to optimize.
URLs also appear in Google’s search results and are read by users – precisely the people you are ultimately optimizing for! So make sure that your URLs are short, easily to read and appear to be trustworthy. Your website will then benefit from a higher click-through-rate (CTR).
Optimize images
Optimize any images you use – and benefit from quicker load times.
- Compress image files before uploading them to the server. We recommend tinypng.com, which is free to use and compresses .png and .jpg files without loss of picture quality.
- Define image size in pixels. When embedding images on your site, give their measurements in pixels and upload them directly in the required size. Webmasters often upload images which are far too large which then need to be reduced on the website. Browsers still need to load the entire file, only to then display a smaller version.
- Give your images an image title and an alt attribute. Google can’t see and understand images and it will still be a while until that’s the case. So help crawlers to interpret images with the help of titles and alt attributes. Don’t forget to use important keywords which you want to optimize.
- Keywords in image URL. Use keywords in both file names AND in the image URL. It might only have a small effect but every little helps! And it’s not very time-consuming so it’s well worth giving it a go.
Conclusion
If you’re happy you’ve implemented all the tips we highlighted in par tone, get to work on these five extra measures. Remember, get it touch with any queries – and good luck!