 Español
Español



El archivo robots.txt es un archivo de texto sin formato, que sirve para dar instrucciones a los rastreadores de Google e informarles qué áreas de una página web se pueden rastrear y cuáles no. El archivo, se sitúa en el directorio raíz (root) en el servidor web. Cuando un rastreador llega al sitio, lo que este hace en primer lugar es «leer» este archivo. En general, el rastreador sigue las instrucciones que se dan allí. El protocolo se llama Robots-Exclusion-Estándar-Protocol. Crear este tipo de archivos robots.txt tiene sentido para mejorar la indexación web y el crawl budget, aunque no es obligatorio.
Podemos excluir URLs individuales y directorios completos del rastreo. Incluso podemos dar instrucciones al robots.txt para que ni una sola página de todo el dominio sea visitada por el robot.
Allow o disallow
En principio hay «solo» dos tipos de información: «allow» y «disallow» (permitir o no permitir). Esto se explica casi por sí mismo. Por regla general, Google puede rastrear todos los archivos de un dominio. Si por lo contrario, queremos excluir algunos directorios o URL del rastreo, añadimos «disallow» por delante y le asignamos un nombre al directorio. Con indicar el enlace relativo es suficiente:
Por ejemplo
Disallow: /admin
De este modo, estaríamos excluyendo del rastreo el directorio de admin de una instalación web. Hay otros directorios a los que tampoco es necesario que el robot acceda, por lo que se pueden incluir en más líneas hacia abajo.
Disallow: /wp-admin/
Disallow:/xmlrpc.php
Con el comando Allow pasa justo, al contrario. Hay un directorio que no tiene que ser rastreado, pero puede haber una URL que, si debe ser rastreada, aunque este dentro de ese directorio. Aquí se puede crear una nueva línea que comienza con «Allow” para crear una excepción. De este modo, estaríamos diciéndole al motor de búsquedas “quiero que ignores todas las URLs del directorio excepto esta”
Disallow según tipo de archivo
Mediante el uso de /* también se pueden excluir ciertos tipos de URL del rastreo. Aquí podemos ver algunos ejemplos:
Excluir todos los archivos GIF:
Disallow: /*.gif$
Bloquear el acceso a todas las direcciones URL que usen el signo de interrogación (?)
Disallow: /*?
Bloquear acceso a urls que comiencen con la palabra «privado».
Denegar: /privado*/
Instrucciones para robots específicos
Los rastreadores y los robots se identifican con un nombre específico en el servidor. Estos pueden determinar para qué rastreador deben aplicarse las normas a través de un comando en el robots.txt. Con un asterisco * indicamos que todos los rastreadores deben seguir esa regla. Google utiliza varios agentes de usuario (user agents) para rastrear la web, puedes revisarlos en la página de soporte de Google:
https://support.google.com/webmasters/answer/1061943?hl=es
El agente de usuario «Googlebot» es especialmente importante. Si deseamos bloquear con robots
.txt una página solo para este agente y no para otros rastreadores, debemos colocar el siguiente prefijo delante de la regla disallow:
User-agent: Googlebot
De este modo, se puede definir exactamente que regla ha de seguirse para cada rastreador.
Aquí tenemos un ejemplo de robots.txt
User-agent: Bingbot
Disallow: /fuentes/dtd/
User-agent: *
Disallow: /fotos/
Disallow: /temp/
Disallow: /example.html
La primera parte se refiere a las reglas que debe seguir el rastreador de Bing y la segunda parte sirve para el resto de los rastreadores.
Incluir robots.txt en el site map
El mapa del sitio es un documento que enumera la diferente urls del dominio. Google también recomienda señalar la ubicación del mapa del sitio en el archivo robots.txt, ya que es el primer archivo que leen los rastreadores.
Incluye simplemente una última línea con el mapa del sitio:
Sitemap: https://www.example.com/sitemap.xml
El motor de búsqueda encontrará directamente el mapa del sitio y lo tendrá en cuenta en el tratamiento posterior de los datos, para comprender la estructura de las páginas.
Las cosas que debes saber
- El robots.txt no es vinculante para los rastreadores y puede ser ignorado en ocasiones. Aunque por lo general, los rastreadores siguen estas reglas.
- El robots.txt no impide la indexación. El rastreador puede llegar a la url desde vínculos externos o enlaces internos y añadirlos al índice.
- Si bloqueamos una página que ya estaba incluida en el índice, Google la seguirá mostrando en el resultado. Para asegurarnos de que Google no indexa la url, debemos permitir que vuelva a rastrear la página y acto seguido indicarle que no la indexe. ¿Cómo lo hacemos? Para ello, es preferible utilizar Meta Robots . En concreto, la meta etiqueta noindex, follow. Esta etiqueta se debe colocar en el código html de la URL, es decir debemos introducir entreyla siguiente información:
<meta name=»googlebot» content=»noindex» />
Prueba el archivo robots.txt con la Google Search Console
Una y otra vez hemos hecho hincapié en varios artículos acerca de la importancia de la Google Search Console para los webmasters. Google muestra aquí si hay problemas para leer el archivo robots.txt.
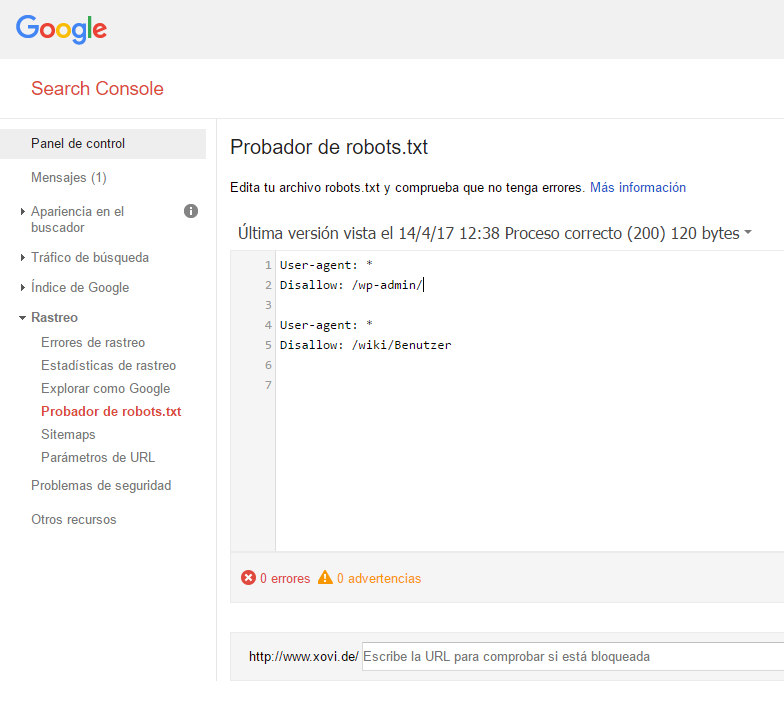
Puedes comprobarlo haciendo clic dentro del menú “Rastreo” en el subapartado “Probador de robots.txt.” Ahí se muestran los errores y advertencias. En nuestro ejemplo, no hay errores o advertencias encontrados así que todo está bien.
Se trata de una instalación de WordPress, que excluye la Admin-URL. El comando «Allow» hace que una url de admin quede exenta de esta prohibición.Es decir, puede ser rastreada aunque pertenezca a este directorio.
Así se prueba un archivo robots.txt en Google Search Console:
- Abre el probador de la página web y desplázate por el código del archivo robots.txt para determinar las advertencias de sintaxis y errores de lógica. En la parte inferior podrás ver el número de errores detectados en el archivo.
- Inserta en la barra inferior una url de tu página web.
- Selecciona en el cuadro situado junto a URL el user agent. Por ejemplo, Googlebot.
- Haz clic en el botón “probar” para iniciar la prueba.
- Comprueba si el botón “probar” indica “aceptada” o “bloqueda” para saber si los rastreadores de Google pueden acceder a la URL introducida
- Edita el archivo y ejecuta la prueba de nuevo, si es necesario. Nota: Los cambios que realices en la página no se almacenan en el sitio.
- Añade los cambios en el archivo robots.txt de tu página web, para que queden guardados.
Fuente: https://support.google.com/webmasters/answer/6062598?hl=de&ref_topic=6061961